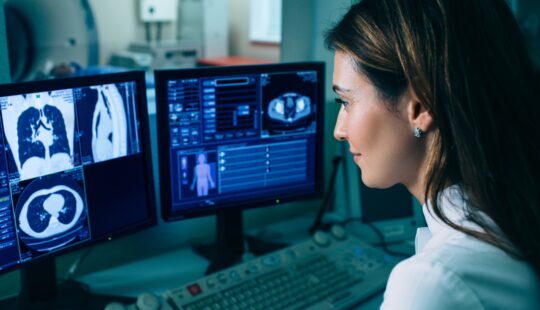
SAP Announces Q1 2024 Results WALLDORF — SAP SE has announced financial results for the first quarter of 2024. Press Release by SAP News April 22, 2024
Corporate Blog SAP’s Adoption Revolution: When Expectations and Outcomes for Cloud Transformation Meet The new Customer Services & Delivery Board area makes it easier and faster for customers to adopt SAP solutions. Blog by Thomas Saueressig April 2, 2024 Read more blogs